
An agent that can't remember is an assistant that starts every morning with amnesia. You brief it on the customer, the deal stage, the quirks in their setup. It helps. You come back the next day. It knows nothing.
That's where most Claude agents live today. Every session is a clean slate. The context you need lives in your briefing docs, your CRM, your notes from last week's call. Someone has to assemble it every time.
Anthropic's memory layer for Claude Managed Agents changes this. Now in public beta, it gives agents the ability to retain context across sessions, share what they've learned with other agents in the same fleet, and write memory to files that are exportable, inspectable, and auditable. For Australian teams running long-lived production agents, four patterns are worth understanding.
The architecture in 30 seconds
Memory in Claude Managed Agents is filesystem-based. Agents write observations and learned context to files that persist between sessions. Those files can be scoped to a user, a team, or an entire fleet. Because the substrate is files, the memory is not locked inside a proprietary datastore. You can read it, export it, redact specific entries, and feed it into an audit trail. That design decision is what makes the compliance use cases below possible.
Pattern 1: Cross-session deal research
An enterprise sales team using Claude as a deal-prep agent faces a recurring problem. The deal cycle runs for weeks, sometimes months. Each session, the agent needs to be briefed on the prospect's tech stack, the procurement process, the stakeholders who matter, and what happened on the last three calls.
With persistent memory, the agent accumulates that context across conversations. By session ten it has its own notes on who matters and why, its own read on what objections are likely, its own record of what's been tried. The quality difference between a session-one agent and a session-thirty agent is substantial.
For a sales rep managing 10 active deals, cutting prep from 40 minutes to under 10 minutes per deal adds up to 5 hours back per week. At $85/hr fully loaded, that's over $20,000 per rep per year in recovered capacity. The harder number to quantify is consistency: an agent briefing your team at 7am before a high-stakes call doesn't forget the detail your rep mentioned six weeks ago.

Pattern 2: Memory-shared support fleets
Customer support agents running in parallel are typically stateless and isolated. One agent learns a quirk in a customer's Salesforce configuration that causes API timeouts. The next agent that handles the same customer starts from scratch, burns 20 minutes diagnosing the same issue, and the customer notices.
Fleet-level memory changes this. One agent's discovery becomes fleet knowledge. For Australian SaaS companies running 24/7 support across Sydney and Melbourne offices that hand off to offshore teams each evening, this is the operational detail that determines whether support quality holds across timezones.
The failure mode is unscoped fleet memory. If every agent writes to shared memory without structure, you end up with contradictory notes, stale entries, and an agent eventually surfacing outdated information with confidence. Scoping policies are not optional. Per-customer memory, fleet-readable but isolated by customer ID, is the right default for this pattern.
Pattern 3: Audit-ready memory for financial services
Australian financial services firms operating under APRA CPS 230 need to demonstrate operational risk visibility into the systems that support their critical business functions. Long-running AI agents have historically been difficult to fit into this framework. The decision logic is opaque. The agent's reasoning isn't exportable in any meaningful form.
Filesystem-based memory changes the compliance conversation. Every piece of context the agent retains is in a file your team can read. You can show an examiner what the agent knew when it made a recommendation. You can respond to a customer's Privacy Act (1988) data access request by exporting and reviewing the relevant memory files. You can redact entries that shouldn't persist.
This is the design choice that makes long-running agents viable in regulated financial services. Memory that lives in a vendor's proprietary datastore, inaccessible to your audit process, creates exactly the visibility gap CPS 230 is designed to prevent. The filesystem approach isn't elegant. It's auditable, and that matters more.
Pattern 4: Memory as a substrate for autonomous loops
The fourth pattern is the most technically interesting. Because memory mounts onto the same filesystem that Claude's tool use accesses, an agent running an autonomous loop can read its own prior notes, reorganise them, and decide what to prune. The memory isn't passive storage. It becomes something the agent actively curates.
Anthropic's benchmarks show their latest models write more coherent, better-organised memory files when filesystem access is the substrate rather than a constrained write API. For Australian teams building autonomous compliance-monitoring loops or weekly research agents, this compounds across runs. The agent's accumulated knowledge of your regulatory environment grows more useful each week rather than resetting.
When memory adds complexity without value
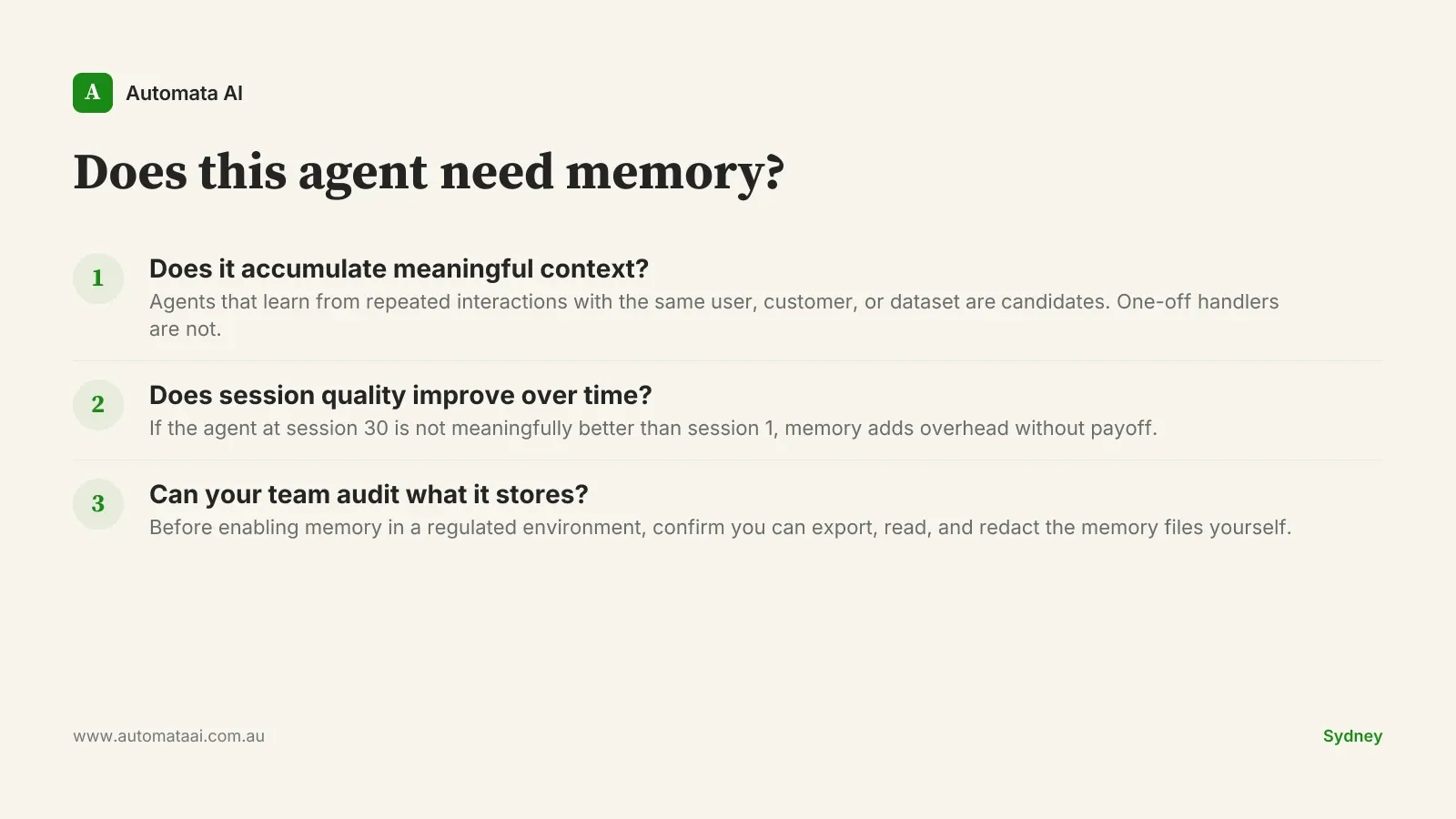
Memory is the right tool for agents that get meaningfully better the more sessions they run. It is the wrong tool for most agents.
A document-processing agent that extracts invoice line items and posts them to your accounting system doesn't need to remember anything between runs. Adding memory introduces a new class of failure: stale or incorrect entries surfacing into decisions they shouldn't affect. The same logic applies to single-session agents, one-off query handlers, and trigger-based automations that run once per event. None of them benefit from memory. The added complexity of scoping, pruning, and auditing memory files is pure overhead.
Before enabling memory on any agent, ask one question: does this agent get meaningfully better at its job the more sessions it accumulates? If the answer is no, skip it. Most agents teams are building today don't clear that bar.
Three things to do before you go live
Audit your agents for memory wins. Anywhere your team currently re-briefs an agent at the start of each session is a memory candidate. List those touchpoints and rank by session frequency.
Define scoping before writing the first memory file. Per-user, per-team, per-fleet. Memory without deliberate scoping becomes a data governance incident. In a regulated environment, it becomes a CPS 230 finding.
Prove the export path early. Before any memory-enabled agent reaches production, run a test export and confirm a non-technical stakeholder can read and interpret what the agent has stored. If you can't explain it, you can't audit it.
The teams that get real value from Claude Managed Agents over the next 12 months are the ones that treat memory as an architectural decision, not a feature to enable. The patterns above are starting points. Scoping policies, audit frameworks, integration with compliance workflows. That's where the work is.


