
Your Claude deployment is live and your dashboards are green. Latency is under 400ms, error rate is near zero, the weekly ops report shows no incidents. Then a client emails to say the output quality has been degrading for two weeks.
That's not a hypothetical. It's roughly the failure pattern Anthropic described in a recent postmortem covering three separate production incidents. For Australian businesses running Claude in revenue-critical or customer-facing workloads, the document is worth reading carefully. Not because the incidents are alarming, but because of what they reveal about how production reliability works at this layer of the stack. Most AU teams haven't had to think about it yet. That's about to change.
What the postmortem covered
Three separate incidents with different root causes: an inference infrastructure failure, a deployment-ordering bug, and a model-behaviour regression that slipped through evals. The first two are familiar engineering problems. The third is the one worth studying.
Anthropic detected several quality issues through user-reported regressions before traditional alerting fired. Status updates went out within minutes of detection. And the postmortem was published at all. Frontier AI labs rarely do that. The transparency is useful, but the lesson underneath it is more important: quality degradation at the model layer is a distinct failure mode from infrastructure failure, and it requires a different detection strategy. Most AU production teams are set up to catch one but not the other.
Three reliability lessons for Australian Claude operators
1. Quality telemetry is not the same as uptime monitoring
Most Australian teams running Claude in production have solid latency and error-rate monitoring. Latency dashboards are easy. They come standard with any observability stack. Output quality monitoring is different. It requires sampling responses, running them against rubrics or evaluation models, and tracking coherence and task-completion rates over time. None of that fires from a standard APM tool. You have to build it deliberately, and most teams don't until something goes wrong.
The cost to instrument quality monitoring properly sits between $20,000 and $60,000 for a typical AU mid-market deployment, depending on output volume and complexity. It is not a trivial line item. It pays back the first time it catches a regression before your customers do. This kind of telemetry layer is part of what we build during production-stage engagements. Our AI Automation Services cover the full stack from eval design through to live monitoring.
2. Eval suites need a named owner, not an annual audit
One regression in Anthropic's postmortem slipped through evals because the suite hadn't been updated to reflect recent user behaviour patterns. The suite was running. It just wasn't current. This is the most common eval failure mode in AU mid-market deployments: suites written once during the build phase, signed off by QA, and then left untouched for six months or a year. The model layer keeps changing. The eval suite doesn't.
User behaviour patterns change. Prompt distributions shift. Customers start using your AI feature in ways the original eval set never covered. A monthly review cadence, with a named individual accountable for updates, catches this. Not a team, not a committee. One person with a calendar invite. Most AU teams who are honest about their eval cadence are running annual reviews at best, and discovering regressions through support tickets at worst.
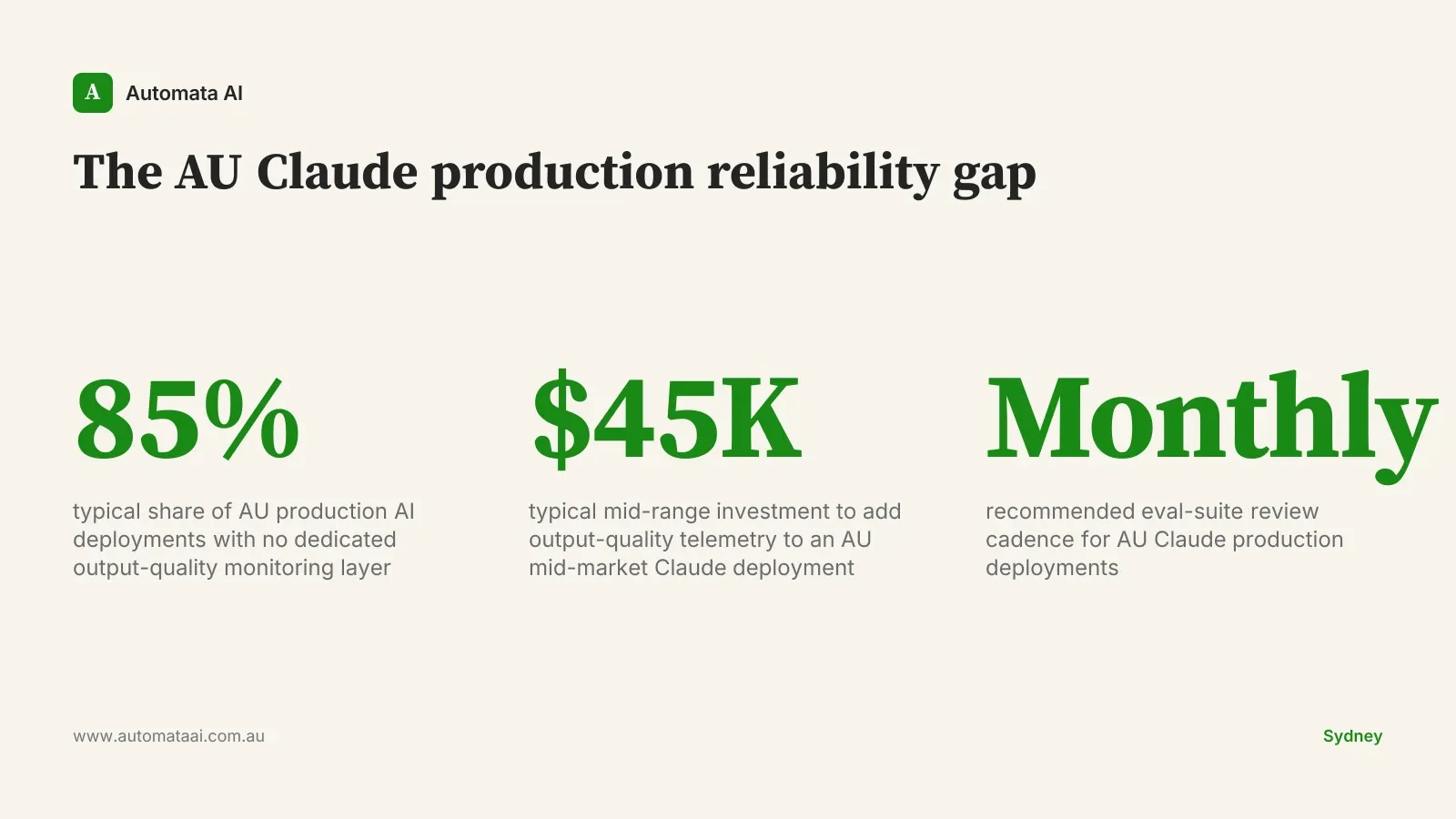
3. Communication speed is a CPS 230 obligation, not a courtesy
Anthropic posted status updates within minutes of detection during each incident. For an API serving millions of users, that's the expected posture. For Australian financial services operators running Claude within their own customer-facing products or internal decision workflows, the stakes are different and the obligation is explicit.
APRA CPS 230 requires material operational incident communication within defined timeframes. An AI quality degradation that affects customer outcomes qualifies. A loan-assessment workflow that starts producing incorrect summaries, or an automated advice system that begins hallucinating product details, is a material incident under that standard. Most AU financial services teams have not mapped AI-specific failure modes onto their CPS 230 operational risk register yet. Our financial services AI practice covers this mapping as part of engagement onboarding.
When this posture is overkill
Not every Claude deployment needs a quality telemetry dashboard and a monthly eval refresh cadence. If your deployment is internal-only, low-stakes, and produces no customer-facing outputs or regulatory-relevant decisions, the overhead is not justified. A Claude integration summarising internal meeting notes for a team of 15 doesn't need CPS 230 mapping or a $30,000 monitoring build. The right approach scales to the actual risk profile, not the maximum possible one.
The threshold is this: if a quality degradation in your Claude outputs would affect a customer interaction, a regulated decision, or a revenue-critical workflow, you need this posture. If none of those apply, you don't. Be honest about which category you're in, because most organisations running 'internal' Claude tools are one integration step away from customer-facing outputs. The line between internal tooling and production risk is thinner than most organisations realise until something goes wrong.
The AU Claude operator four-part reliability checklist
The following checklist applies to any Australian team running Claude in a production workflow where output quality matters. It is designed to be completed in a fortnight, not deferred to a quarterly planning cycle.
Audit your alerting. Determine whether your monitoring stack covers output quality, not just latency and error rate. If it doesn't, scope the telemetry build before the next sprint.
Assign an eval owner. Name one person responsible for monthly eval suite reviews. Give them the time and calendar space to do it properly.
Define your AI incident comms SLA. Document what constitutes an AI quality incident, who gets notified, and within what timeframe. If you are in financial services, map this to your CPS 230 operational risk register.
Run a quality baseline. Sample 50 to 100 recent Claude outputs from your live system and grade them manually. That baseline is your regression reference point for everything that follows.

The businesses that catch Claude quality regressions in their telemetry before their customers do are the ones that built reliability as an engineering discipline, not an assumption. That posture takes two weeks to establish. Start with the eval owner — everything else follows. If you want to pressure-test your current production setup against this checklist, an AI Readiness Assessment is the right starting point.


