
A tool definition changed on a Tuesday afternoon. The agent still responded. Same latency, same confidence. It just stopped calling the tool it was supposed to call, and nobody noticed until a Sydney financial services client raised a support ticket three days later.
That is the failure mode that chat-based testing misses. You run the agent, it returns a plausible answer, you ship. Two weeks later a renamed parameter or a schema version bump breaks the contract silently, and the degradation looks like model drift. It is usually a one-line fix.
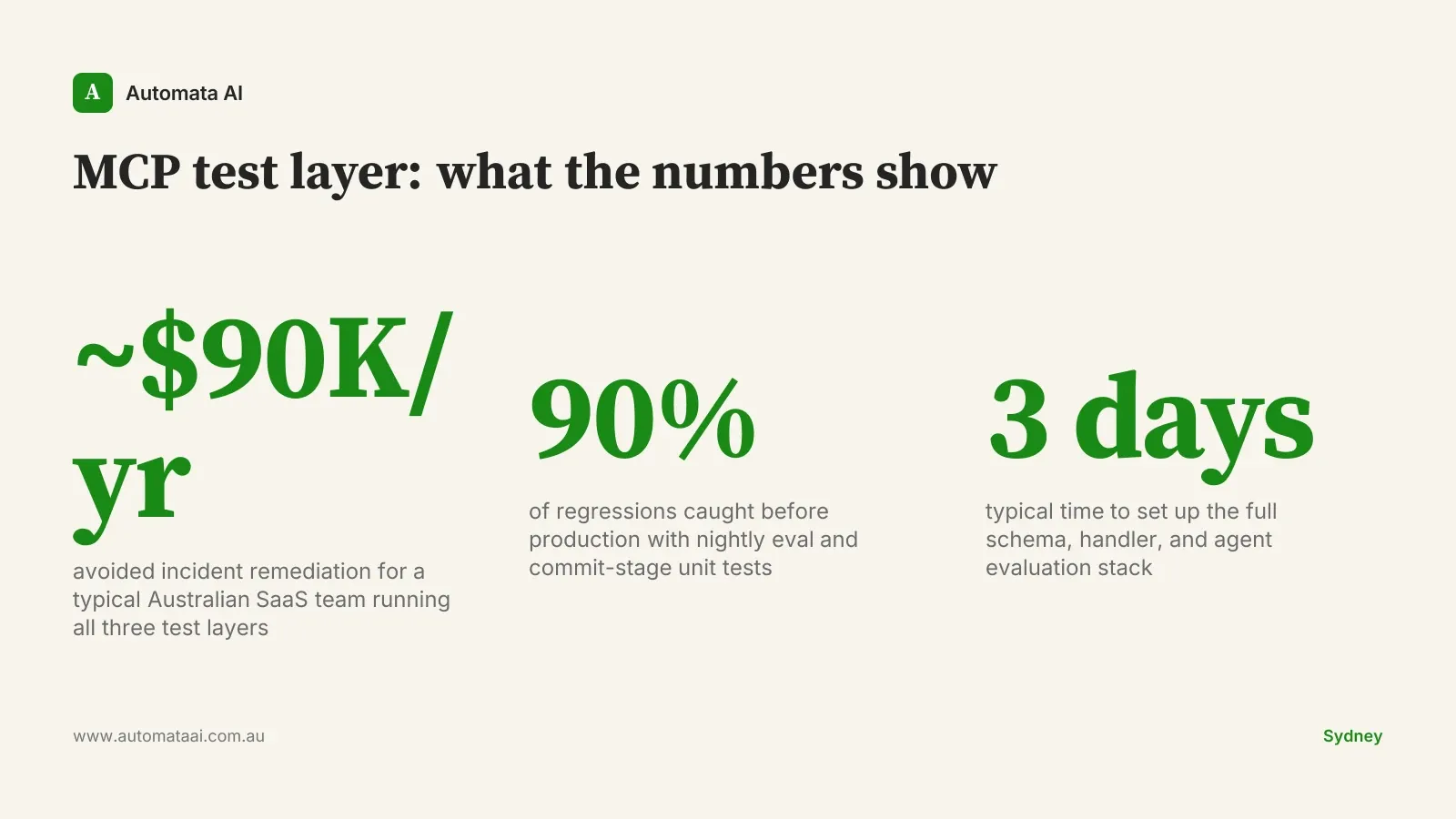
A repeatable test layer for an MCP server takes roughly three days to build. It pays back the first time it catches one of these.
The four layers worth testing
Tool schema. Each tool definition is a contract between your server and the agent calling it. It should round-trip through your validation library. Pydantic for Python, Zod for TypeScript. If the schema cannot be reconstructed from your validation model, the contract is already ambiguous.
Handler logic. Unit tests that call each handler with valid and invalid inputs and assert the response shape. These should run in under a second each and execute on every commit.
Agent evaluation. A small harness that calls Claude against eight to twelve canonical prompts and asserts the correct tool is called with the correct arguments. This layer is slow. Run it nightly, not on every commit.
Error envelope. Every error path should return a structured MCP error response. If the agent receives an unhandled exception, it cannot recover gracefully. Test each error path as a structured response, not as a side-effect of broken code.
A reference stack
For Python, pytest with a thin wrapper around the MCP SDK handles schema and handler tests. FastMCP ships test utilities that manage the server connection lifecycle, which removes the boilerplate of setting up and tearing down the server in each test. For TypeScript, vitest with the MCP SDK testing utilities does the same job. Both stacks run fast enough to sit in a pre-commit hook or a commit-stage CI job.
The agent-evaluation layer sits outside both stacks. A harness that instantiates a Claude client, sends canonical prompts, and inspects the resulting tool_use block for tool name, argument keys, and argument values where those values are deterministic. Eight to twelve prompts covers the main flows. Three to five covers edge cases. One or two covers known error paths where the tool should return a structured failure, not a successful result.
If you are unsure whether your current MCP design will hold up under real conditions, the AI Readiness Assessment covers the design decisions that most commonly cause evaluation failures: ambiguous tool names, overlapping parameter semantics, and missing error contracts.
The three-layer MCP test stack
The pattern that holds across the teams we work with is three layers: schema validation on every commit in under five seconds; handler unit tests on every commit with the suite completing in under thirty seconds total; agent evaluation on a nightly schedule against a stable set of prompts. A Brisbane SaaS team running this stack caught a parameter rename that would have broken their document-processing flow the day before a client demo. The regression surfaced in the nightly evaluation run at 2 a.m. Fix time was forty minutes the next morning.

When not to build the test layer
If the MCP server is a proof-of-concept with no defined path to production, skip the evaluation harness for now. The eval layer requires stable canonical flows. You need to know what the agent is supposed to do before you can write a test that asserts it is doing it. Building the harness around an unsettled interface produces brittle tests that break when the design changes, which erodes confidence in the test layer before it has had a chance to earn any.
The trap is using test coverage as a substitute for design clarity. A well-tested bad interface is still a bad interface. The evaluation harness should follow a stable tool definition, not try to stabilise one.
Once the server is downstream of a real business process, that calculus reverses. A schema change without a failing test in CI is a production incident with a scheduled start time.
Test the unhappy paths first
The interesting bugs in MCP servers are not in the happy path. They are in rate limits, partial failures, idempotency, and retries. An agent that calls a tool twice because the first call timed out but actually succeeded needs to handle that outcome correctly, or it produces a duplicate action with real downstream consequences. The test for this is a handler test that fakes a slow first response and a normal second response, then asserts the downstream state is consistent. Most builders skip this test until they hit it in production.
Australian teams building on APRA-governed services covering payments, credit, or custody have additional reason to test these paths carefully. A structured error response that the agent can reason about is categorically different from an unhandled exception that terminates the flow and leaves the system in an unknown state. Under APRA CPS 230, operational resilience obligations now extend to AI tooling, not just the core platform. The error path tests are the ones that satisfy an auditor.
What the numbers look like
Add three numbers to a shared dashboard from week one: time-to-first-result on the agent flow, cost-per-task in tokens, and nightly evaluation pass rate. Unit test pass rate tells you the code has no syntax errors. Evaluation pass rate tells you the agent is still doing what it was designed to do, at the prompt level, against the actual model. Both numbers belong on the same screen. Without the evaluation pass rate, you will not know a regression has happened until a human notices the output is wrong.
A Sydney engineering platform team running this discipline across three MCP servers reports roughly $90,000 a year in avoided incident remediation. Fewer weekend escalations, faster triage when issues appear. A failing evaluation prompt identifies the regression in minutes rather than hours of agent tracing. Run your own numbers in our ROI Calculator. The payback on an instrumented MCP layer is typically under six weeks.
The mindset that makes it compound
Teams that treat their MCP servers like internal APIs, with documented contracts, test coverage, and version discipline, have fewer surprises as the server ages and the surrounding systems change around it. Teams that treat them like chat sessions with extra steps tend to rediscover the same failure modes every six months, usually at the worst moment. Our AI Automation Services include MCP design and test-layer setup as a standard deliverable, because a server that ships without a test harness is one we will be debugging under pressure six months later.
Pick one MCP server that is already in production or heading there. Add schema validation tests this week. Add handler unit tests next week. Schedule the evaluation harness for before that server touches a second business-critical flow. Run the evaluation nightly. Three weeks of work, not three months. The server starts behaving like the infrastructure it is, and the next tool definition change stops being a risk.


