CodeRabbit reviews around 2 million pull requests every week across 15,000 customers, and its team has watched one failure mode show up more than any other in AI-generated code: the change compiles, the tests pass, and the work still does not solve the problem it was asked to solve. Their answer is to spend more Claude tokens upstream of code generation, not less, by running a dedicated planning loop that uses several Claude models in concert. The pattern is one of the cleanest agent-orchestration templates published in 2026, and the version that survives contact with regulated Australian engineering work is worth studying.
Why planning is the bottleneck, not the model
David Loker, VP of AI at CodeRabbit, traces most agent failures to a single root. Senior engineers internalise context (the constraints of an upstream system, the customer that one feature flag protects, the migration debt nobody documents) and then write prompts that assume Claude can see what they see. Vague prompts force the coding step to fill the gaps with whatever sounds plausible. The agent ships code that solves a different problem cleanly. The reviewer rejects it. The cycle restarts.
CodeRabbit's response is to interpose an orchestration layer that runs before any code is written. The layer coordinates Claude to read requirements, name the assumptions hiding in the request, and emit a structured execution plan, which becomes a collaborative PRD validated by the team before Claude Code picks up the build. The plan itself becomes the unit of work that humans argue over, not the diff.
The three-tier Claude routing that holds up at production scale
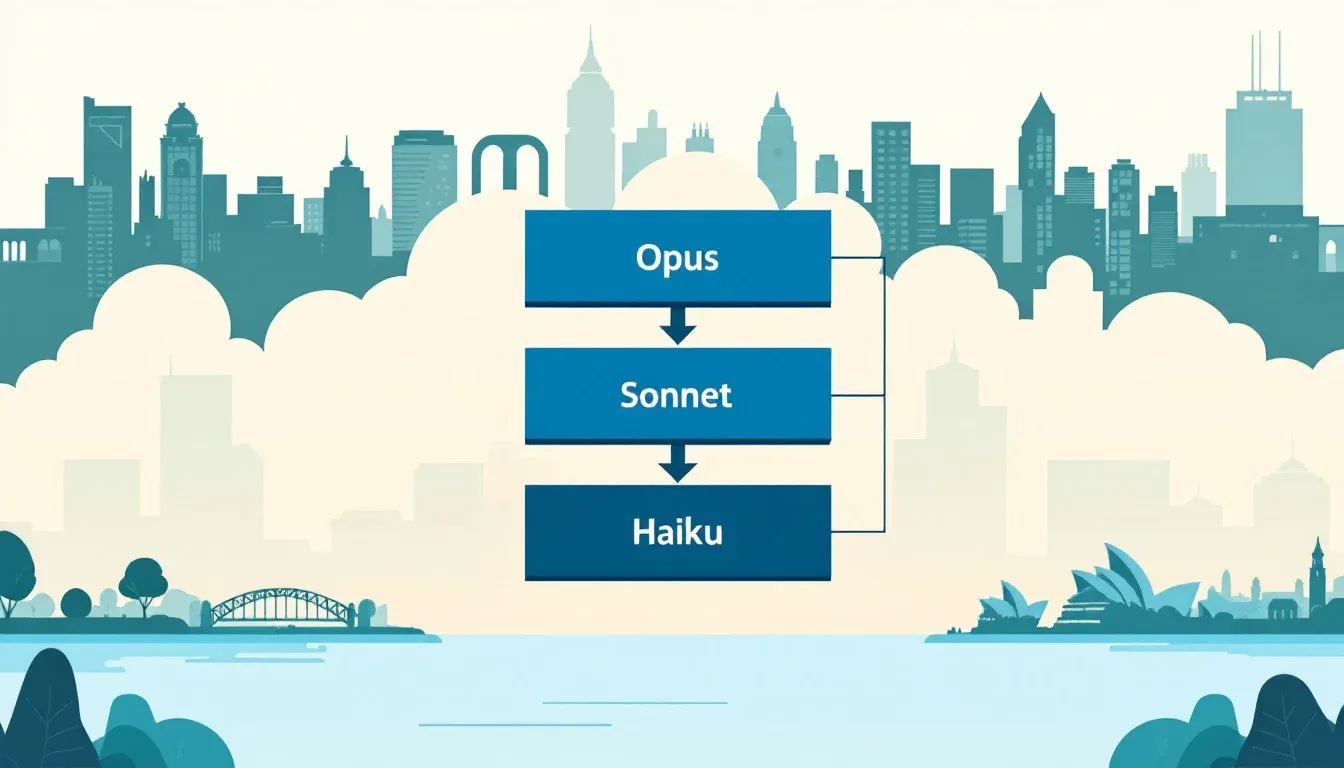
What is novel is not that CodeRabbit uses multiple Claude models. It is that they let an evaluation harness decide which model handles which step, rather than picking by intuition. The current stack:
Opus drives the orchestration loop and any strategic work where wrong-on-direction is far more expensive than wrong-on-detail. Architecture review, ambiguity resolution, cross-PR pattern recognition.
Sonnet sequences the orchestration output into structured planning steps. The slot where the planning intent becomes a checklist a senior engineer can argue with.
Haiku handles narrowly scoped operations such as context distillation, targeted tool use, and the dozens of small lookups that would burn Opus tokens for no quality gain.
Loker's discipline is the part most teams skip. 'If Haiku does as well as Sonnet on a given task, we use Haiku. If the eval harness tells us plan quality improves when we give Opus more room, we give it more room. We do not guess.' That sentence is the entire wedge. Most teams pick a model once, glue it everywhere, and end up either over-spending on the easy steps or under-investing on the hard ones.
What an Australian engineering team should copy directly
For a Sydney or Melbourne engineering team running Claude in production, three things copy from the CodeRabbit playbook with almost no modification.
First, separate planning from coding as two distinct sessions, with the plan as a reviewable artefact. The plan becomes the quality gate. If the plan is wrong, the team saves tokens, time, and a code review cycle before any code is written.
Second, route models by evaluation rather than reputation. Build a small eval harness early: a library of LLM judges scoring the dimensions you actually care about, including correctness against the brief, completeness, coverage of the test plan, and regression risk. Run the eval after every model swap. CodeRabbit's harness lets them defend every model choice to their CFO with data.
Third, treat plan quality as the leading indicator for downstream code quality. CodeRabbit measured the same task with and without planning. The downstream effect on accepted code was pronounced enough that the planning step paid for itself in reduced rework, even with the higher per-task token cost.
What to adapt for the Australian regulated context
The straight copy works in a startup. In an APRA-regulated bank, an AUSTRAC-reporting fintech, or a Privacy Act-sensitive healthcare provider, the planning layer needs a governance overlay before it sits in production.
What we add for Australian clients starts with a control map that ties each step in the planning loop to a control the second line of defence already understands. CPS 230 operational risk obligations want named owners, defined controls, and an evidence trail. The orchestration layer is a control surface, and it is cheaper to treat it as such from day one than to retrofit governance after a finding.
Next is a retention policy on planning artefacts. The plan is now part of the audit trail. A typical retention window for an APRA-regulated firm is seven years for system changes that touch in-scope systems. Wire that into the artefact store before the first production run, not after the first audit finding.
Finally, a model-routing policy that the platform team owns rather than the individual engineer. CodeRabbit's eval-driven routing only works when one team owns the harness and the routing config. In an Australian regulated organisation, that team usually sits inside the AI platform group, which reports to the CTO with a dotted line to the CRO. Without that ownership, routing drift turns into a security-review surprise within two quarters.
A 90-day rollout for an Australian engineering team
For an Australian engineering team of 30 to 80 engineers ready to copy this pattern, a working rollout looks something like the following.
In weeks 1 to 3, pick one high-volume internal workflow that already has clear acceptance criteria and a senior engineer willing to own the plan format. Internal migrations, code-review summarisation, and incident post-mortem drafting are good first candidates. The narrower the first slice, the faster the team builds confidence.
In weeks 4 to 6, build the planning loop with Claude. Run it manually, score the plans by hand, and only then write the routing config. Resist the urge to wire in Opus everywhere on day one. The cost discipline is part of the discipline.
In weeks 7 to 10, ship the eval harness. Three LLM judges is enough to start. Score plan correctness, plan completeness, and downstream rework on the implementations. The numbers will surprise the team and will move the routing config more than any architectural opinion would.
In weeks 11 to 13, roll out to a second team and measure rework against the unmodified baseline. The build investment is typically $120,000 to $280,000 AUD all in, and the rework saving for a 50-engineer Sydney shop running Claude Code at scale is usually $450,000 to $850,000 AUD a year. The payback window is short enough that the conversation with the CFO is not difficult.
The honest cost frame
Adding a planning loop costs more Claude tokens, not fewer. The CodeRabbit pattern roughly doubles the per-task token spend compared with single-shot code generation. The reason it still pays back is that the alternative is a senior engineer writing a 90-minute rework note instead of approving a clean PR in 4 minutes. At a fully-loaded Sydney senior engineer rate of around $230,000 AUD a year, three avoided rework cycles a week pays for the extra tokens many times over.
The trap to avoid is letting the planning loop become its own form of busywork. The plan should be terse, opinionated, and reviewable in under 10 minutes. If it reads like a 30-page consulting deck, the team has missed the point, and the planning loop will be quietly disabled within a sprint.
Australian engineering leads sizing this work for an internal rollout can book a working session with our team via the Automata AI contact page. We have shipped the planning-first pattern with Claude into Australian mid-market and APRA-regulated environments, and we keep the playbook short.