Nearly every flagship open model in 2026 uses a mixture-of-experts design. DeepSeek V4 Pro, for instance, carries about 1.6 trillion total parameters but activates only around 49 billion of them for any given token. Those figures sound like pure research trivia. For an Australian business owner sizing a budget, they have a direct effect on what a model costs to run and how predictably it behaves in production. Here is mixture of experts explained in plain English, without the lecture.
The idea in one minute
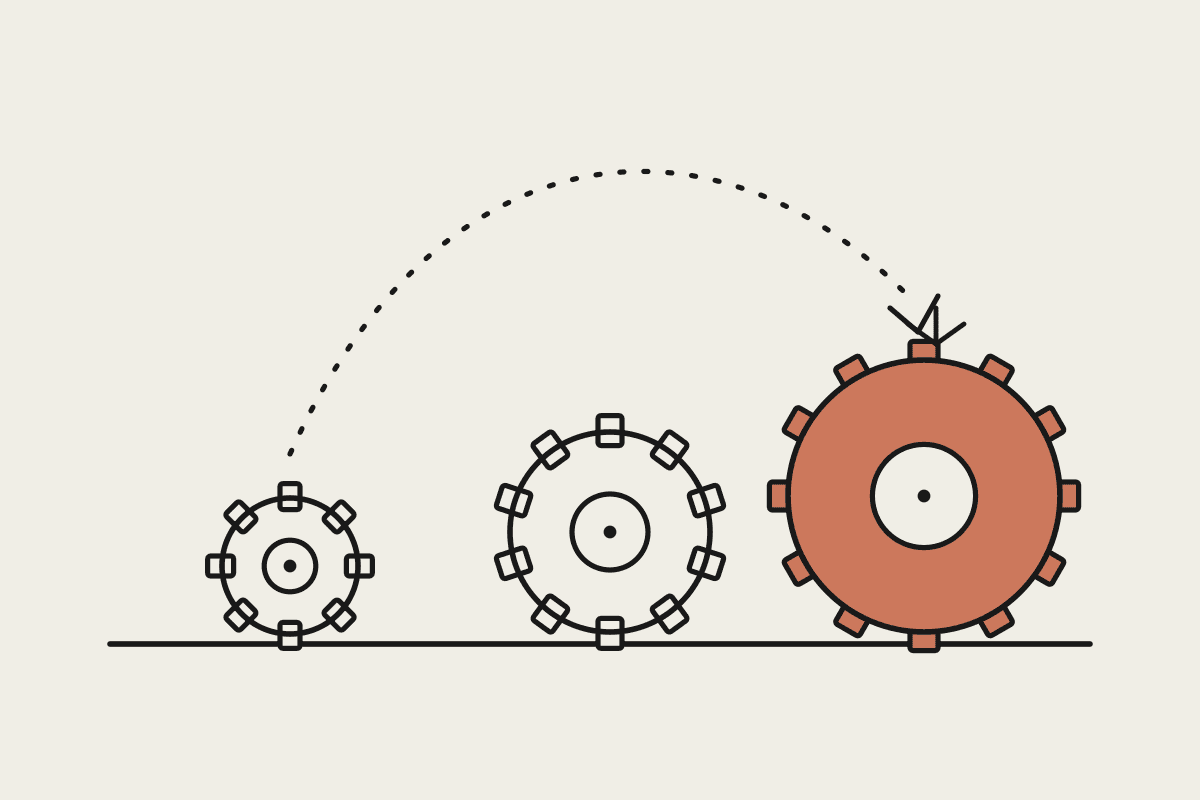
Picture a large consulting firm. You do not put every partner on every job. Someone at the front desk routes each new task to the handful of specialists who actually fit it, and the rest of the firm carries on with their own work. A mixture-of-experts model works the same way. It holds a very large pool of internal specialists, called experts, plus a routing layer that picks only a few of them for each piece of input.
Total parameters are the whole firm on the books, every expert the model could call on.
Active parameters are the few experts actually brought in for a given token.
A routing layer decides which experts handle each request, moment to moment.
This keeps answer quality high while holding the running cost down.
That is the whole trick. A model can look enormous on paper and still behave like a much smaller, cheaper one on each individual request, because most of its experts sit idle at any given moment.
Why the architecture reaches your budget
The split between total and active parameters is not an academic detail. It sets the size of the hardware bill, and a misread here is one of the more common ways an AI pilot overspends before it has proven anything.
Active parameter count is the main driver of memory use and GPU spend per request.
Total model size still affects download time, storage, and how much memory the weights occupy at rest.
Routing can make outputs vary in subtle ways between runs, which matters for testing and sign-off.
Sizing your compute to the total parameter count, rather than the active count, wastes money every month.
A Sydney or Melbourne business that quotes hardware against the headline trillion-parameter figure will end up paying for a fleet it never uses. Quote against the active count and the real concurrency you expect, and the same model fits a far smaller, cheaper footprint.
What this means in dollars
Here is the practical lesson for an Australian small or medium business. A bigger headline number does not mean a bigger bill. A right-sized deployment of a mixture-of-experts model can run on hardware costing under $20,000, because you pay for the active parameters and the actual workload, not the full trillion on the brochure.
A useful rule of thumb when you read any model announcement:
Do not be impressed or alarmed by the total parameter count on its own.
Size compute to the active parameters and your genuine workload.
Run a short test on your own tasks before committing to any hardware purchase.
Re-check the sizing whenever you change model, quantisation, or expected traffic.
A note on quality and consistency
One quirk of mixture-of-experts models is worth planning for. Because the router chooses different experts for similar inputs, the same prompt can produce slightly different answers on different runs. For a marketing draft that is harmless. For a process that feeds a contract, an invoice, or a compliance record, you want a person checking the output before it counts.
Use these models freely for low-risk drafting and internal summaries.
Add a human sign-off wherever an output commits the business or touches regulated data.
Keep a short log of what the model did, so a person can audit a decision later.
This is less about the technology and more about good operating discipline. The model does the heavy lifting, and a person stays accountable for anything that matters. Australian businesses handling personal data also have obligations under the Privacy Act, so that human checkpoint is sound practice as well as good governance.
Open mixture-of-experts models or a managed one
Most of the headline mixture-of-experts releases are open-weight models you can in principle run yourself. That control appeals, especially where data must stay onshore. It also brings real upkeep: hardware to buy, models to patch, and someone competent to keep the whole setup secure.
For most businesses, the sensible default is a managed model for everyday work, with self-hosted open weights reserved for the genuinely sensitive tasks. We build most client systems on Claude, the model family from Anthropic, because it removes the hardware and maintenance burden while staying reliable on the messy, real-world inputs Australian businesses actually send. A typical split looks like this:
Claude through an API for customer enquiries, document work, and day-to-day automation.
A self-hosted open mixture-of-experts model only where data residency or cost at high volume demands it.
A clear written boundary so staff always know which tool handles which kind of task.
A sensible first step
The architecture talk matters less than the decision it supports. Start with one painful, repetitive task, size the compute honestly against active parameters, and measure the result before you scale. Treat a flashy parameter count as marketing, not as a reason to buy a bigger machine.
We translate this kind of architecture detail into a clear plan and a clear price, and we keep Claude as the default where managed simplicity wins. If you want help sizing a model to your real workload, book a brainstorm.