The most common enterprise AI setup in 2026 is not all-Claude or all-open-source. It is hybrid: a frontier model for the hard problems and a cheaper open model for high-volume routine work. Done well, a hybrid stack cuts cost without giving up quality. Done badly, it adds a pile of plumbing you did not need. Here is how Australian teams structure it so it actually pays.
The idea in one line
Route each task to the cheapest model that can do it well. Complex reasoning, customer-facing writing, and anything sensitive goes to Claude. Bulk, low-stakes, repetitive jobs go to a self-hosted open model such as GLM-5.2 or Mistral 3. The skill is in drawing the line in the right place, and then keeping it there.
What goes where
A simple split most teams can adopt on day one:
Send to Claude: contract analysis, nuanced customer replies, code review, and any task where a wrong answer is expensive or hard to undo.
Send to an open model: tagging, classification, first-pass summaries, and internal drafts produced in large batches.
Keep a human in the loop wherever the output touches a customer or a compliance record.
A Sydney support team might run 90 per cent of ticket triage on an open model and reserve Claude for the 10 per cent of replies that need real judgement. The customer never sees the join.
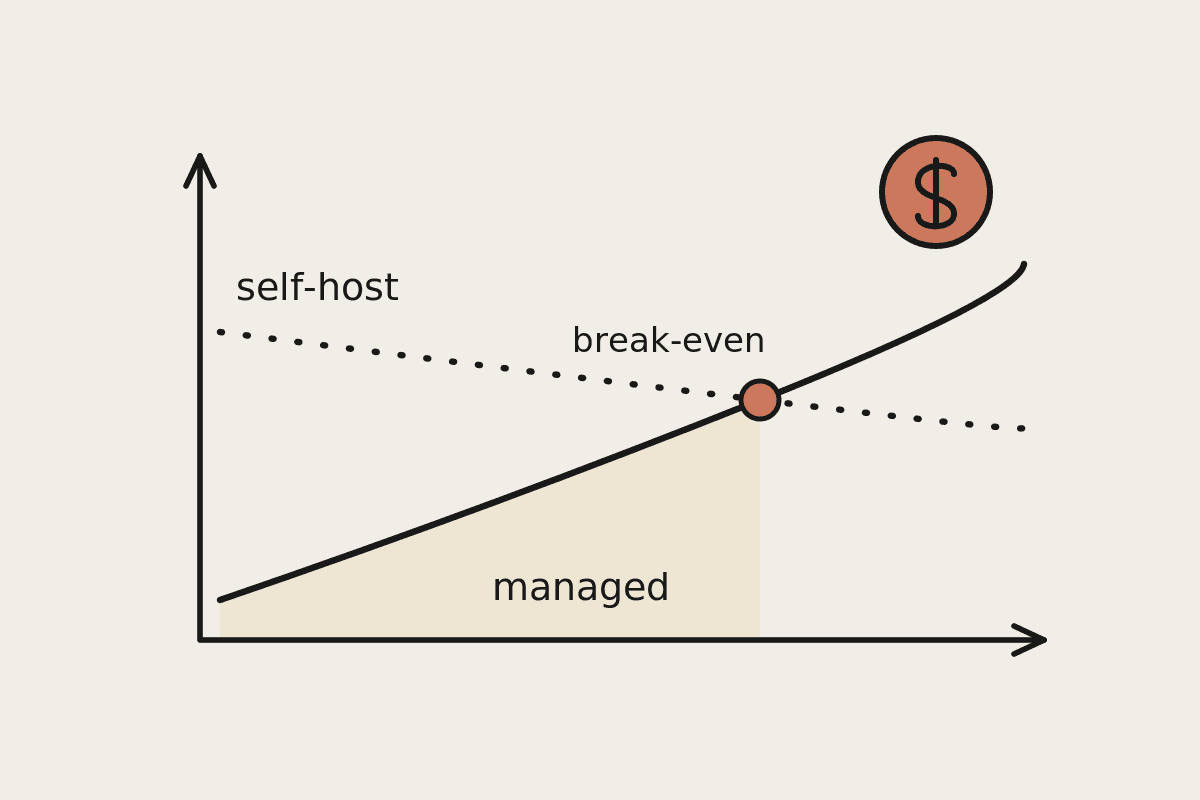
The economics
The saving comes from volume, not from dropping quality on the work that matters:
High-volume routine tasks are where open models are cheapest per request.
The hard 10 to 20 per cent stays on a managed model, so quality and safety hold where they count.
Total spend can fall well below an all-managed bill once routine volume is large enough.
For a mid-size firm, a working hybrid stack can mean the difference between a $6,000 monthly AI bill and a $2,500 one, while the customer-facing quality stays exactly where it was.
The catch
Hybrid is not free to build. You need routing logic, two sets of monitoring, and a clear rule for what goes where. That is engineering work, and it only pays off above a certain scale. Below a few million tokens a day, the simpler all-managed setup usually wins on total cost once you count the build and the ongoing maintenance of two systems instead of one.
Where to start
Do not architect a hybrid stack on day one. The order that works:
Start on Claude and measure which tasks dominate your token usage.
Move only the one or two highest-volume, lowest-risk tasks to an open model once the numbers justify it.
Add routing and monitoring only when you have a second model worth routing to.
That keeps things simple while the saving is small and adds complexity only when it pays for itself. A hybrid stack should be the result of a measurement, not the starting assumption you build everything around.
Common ways it goes wrong
Most failed hybrid stacks fail in the same few ways, and all of them are avoidable. The first is routing on price alone. If you send a task to the cheap model purely because it is cheap, without checking the output quality holds, you save a few cents and risk losing a customer. The split has to be drawn on what each task can tolerate, not on what each token costs.
The second is building the routing before you have the volume to justify it. A hybrid stack carries fixed complexity: two models to monitor, one more failure mode, and a rule set someone has to maintain. Below a few million tokens a day that overhead usually costs more than it saves, and a single managed model is both cheaper and calmer. Add the second model only when one workload is clearly large enough to move the bill on its own.
The third is losing track of which model produced what. When an answer is wrong, you need to know in seconds whether Claude or the open model wrote it, or you will spend an afternoon guessing. Tag every response with its source from day one. A hybrid stack you cannot audit is not a saving, it is a liability dressed up as one.
The short version: a hybrid stack is a destination, not a starting point. Earn your way to it by measuring where your tokens actually go, then move one workload at a time, keeping a clear record of what runs where and why. Built in that order, the saving is real and the system stays easy to reason about. Built the other way around, you have bought yourself complexity and two failure modes you will spend the year regretting, for a saving you could have measured first. Start managed, prove the case, then add the open model where the volume earns it.
Want help designing a hybrid stack that actually saves money? Book a free brainstorm with us.