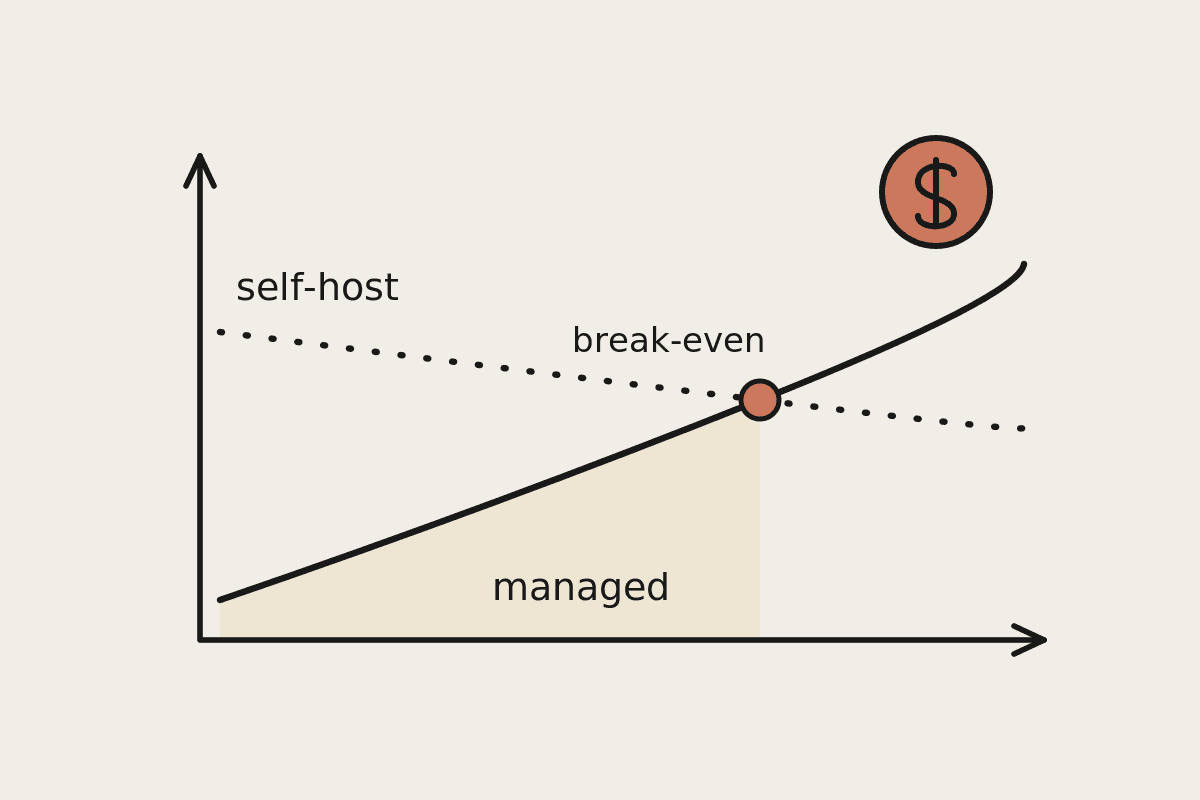
Open-source models are free to license and Claude is not, so the cost question looks settled before you start. It is not. Once you count infrastructure, staff time, and risk, the cheaper option flips depending on how you actually use AI. Here is the honest breakdown for Australian buyers, with the numbers we use on real engagements.
When open source is genuinely cheaper
There are real scenarios where self-hosting an open model wins on total cost:
Very high volume. Above roughly 100 million tokens a day, self-hosting can cut 60 to 70 per cent off a managed bill.
A narrow, repetitive task. If one well-defined job makes up most of your usage, a fine-tuned open model can match quality at a fraction of the per-request cost.
Hard data rules. If a contract or regulator says data cannot leave your control, the open model may be the only compliant option at any price.
A Melbourne firm processing millions of identical document checks a day is a textbook fit, and we would happily help build it.
When Claude quietly wins
For most Australian SMBs, the managed bill is the smaller one once everything is counted:
Low to moderate volume. Under about 5 million tokens a day, a managed API almost always costs less all in.
Mixed workloads. If your tasks vary, you cannot fine-tune your way to savings, and a general model earns its keep across all of them.
No spare engineer. Self-hosting needs 10 to 20 hours a month of upkeep. That salaried time often dwarfs the API saving.
A typical services business spending $300 to $1,500 a month on Claude would spend more, not less, running its own server once the engineer's hours are priced in honestly.
The hidden costs that flip the maths
The reason the comparison fools people is that the free side hides its costs in places a quick quote never looks:
Idle GPU time. You pay for the card whether it is busy or not, so spiky or part-time workloads waste most of what you buy.
Setup and migration. Two to four weeks of senior engineering to reach production is real money before a single token is served.
Risk and downtime. When a self-hosted model goes down on a Friday, the cost is your team's time and a stalled workflow, not a support ticket someone else owns.
The number that decides
The benchmark score rarely settles this. Two numbers do: your daily token volume and your data obligations. We ask clients to measure both before committing to either path.
Track real token usage for a full month, not a busy day.
Write down any genuine data residency requirement, with the clause that creates it.
Only then compare a managed quote against a fully loaded self-hosting estimate, hardware plus salary plus risk.
The pragmatic answer
Most firms get the best economics from a managed model now, with the option to move a single heavy workflow to open source later if volume justifies it. That keeps cost low today and leaves the door open as you grow. The decision is reversible, so make the cheap, low-risk choice first and upgrade only when the numbers force your hand.
A worked example
Picture a Melbourne services firm sending about 3 million tokens a day through Claude and paying somewhere around $900 a month. The open-model pitch says the licence is free, so the bill should fall to zero. It does not. A single-GPU box in an Australian region runs $1,500 to $3,000 a month before anyone touches it, which is already more than the managed bill it was meant to replace.
Now add the parts that do not appear in the quote. Two to four weeks of setup, then 10 to 20 hours a month of upkeep at a senior engineer's rate. Add the morning the model stops responding and someone drops their real work to restart it. The free model has quietly become the more expensive one, and the firm is now carrying operational risk it did not have before.
Flip the volume to 200 million tokens a day and the same arithmetic reverses just as cleanly. The hardware cost is now spread across so many requests that the per-token saving overwhelms the upkeep, and self-hosting pulls clearly ahead. The lesson is not that one path is always right. It is that the answer is a function of volume, and you cannot read it off the licence.
Want us to model both options against your real usage? Book a free brainstorm and we will run the numbers.