"The model is free" is the most expensive sentence in Australian AI right now. You can download the weights for a model like GLM-5.2 or a recent Llama release without paying a cent, and the published benchmark numbers are genuinely strong. The trap is reading "free download" as "free system". A real production deployment carries a monthly bill that catches most business owners off guard, because the cost simply moves off the licence and onto your own infrastructure and your own people.
We field this question most weeks at Automata AI, usually from a Sydney or Melbourne owner who has read that open-source models now rival the closed ones. On paper, they do. The question that actually decides anything is what running one costs you across a year, and whether that figure beats paying for a managed model by the token. Here are the honest 2026 numbers so you can budget with your eyes open.
What self-hosting actually means
Self-hosting means you run the model on hardware you rent or own, instead of calling someone else’s API. In practice that is a GPU server sitting in an Australian cloud region, the software stack to serve the model, monitoring so you find out when it breaks before your customers do, and an engineer who understands the whole chain. The model weights themselves are the cheapest item on that list. Everything wrapped around them is where the money actually goes.
The three infrastructure cost tiers
Australian self-hosted deployments fall into rough monthly bands, depending on how much traffic you push through them and how much downtime you can live with:
Small, single-GPU: roughly $1,500 to $3,000 a month. Fine for light internal use, testing, and low-traffic tools.
Mid-tier production: about $5,000 to $15,000 a month. Handles steady traffic for one or two busy workflows.
High-availability production: $15,000 to $40,000 a month. Redundant hardware so the service stays up when something fails, which it eventually will.
Those figures are infrastructure alone. They assume you already have someone on the team who can stand the system up and keep it running. If you do not, the true figure is higher than any of those bands suggests.
The costs the brochure skips
The GPU invoice is the visible cost. The ones that quietly add up sit on your payroll and your risk register:
Setup labour: two to four weeks of senior engineering time to reach a stable first deployment. At Sydney contractor rates, that is real money before you serve a single request.
Ongoing upkeep: 10 to 20 hours a month for patching, monitoring, security fixes, and moving to newer model versions as they ship.
Risk cover: when the model produces a bad output or the service goes down, you absorb it. There is no vendor support line to ring at 2am.
For most firms the salaried engineering time is the single largest real cost, and it never appears on the cloud bill. A capable AI engineer in Australia is not a cheap hire, and the work does not stop the day the system goes live.
Compare it against a managed Claude bill
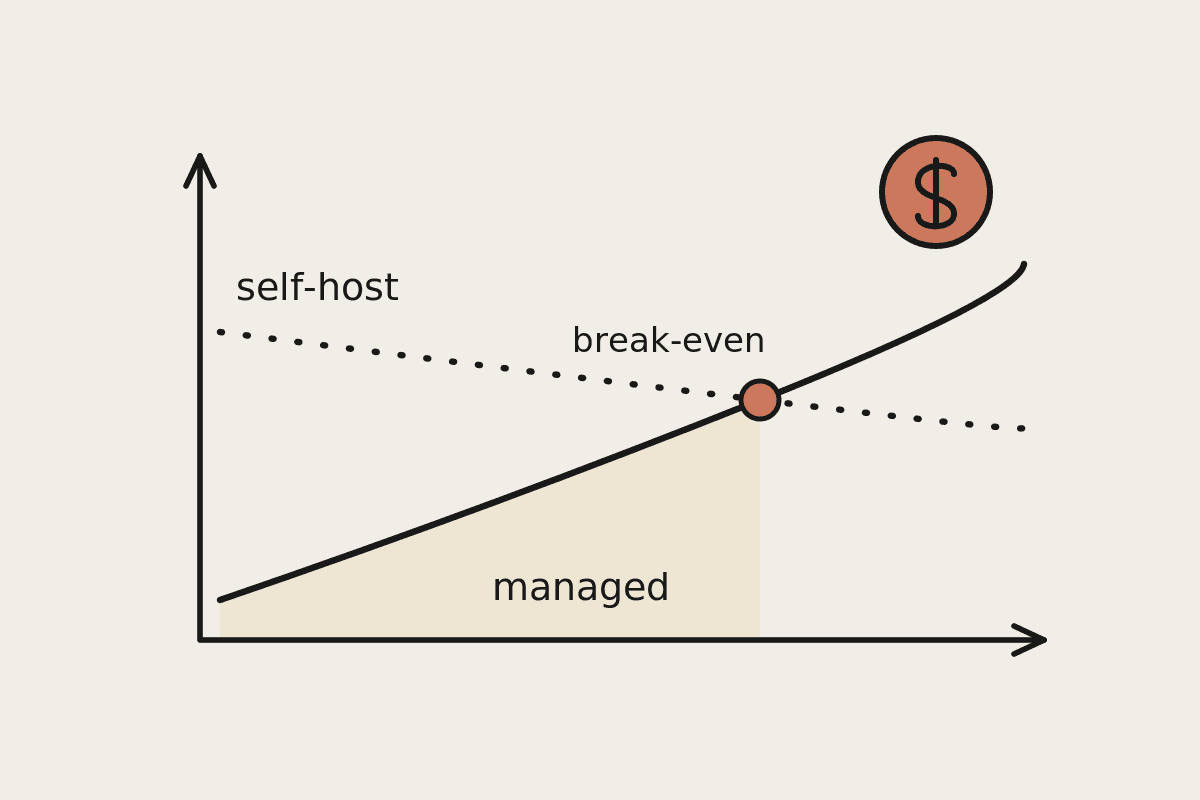
A managed model such as Claude charges per token and runs on someone else’s servers, so your fixed cost is close to zero. For a Sydney services business sending a few hundred thousand tokens a day, that often lands between $200 and $1,500 a month all in, with no engineering overhead attached. Self-hosting only starts to win once your volume is high enough to spread those fixed costs across millions of requests.
A rough breakeven, drawn from the deployments we have seen this year:
Under 5 million tokens a day: a managed API almost always wins on total cost.
Between 10 and 30 million tokens a day: the two paths converge, and the decision turns on your data rules rather than the dollars.
Over 100 million tokens a day: self-hosting can save 60 to 70 per cent, provided you have the team to run it well.
Very few Australian small and mid-sized businesses are anywhere near that top band. Most sit comfortably in the first one, where a managed model is both cheaper and a great deal less work.
Where data residency changes the maths
Cost is not the only input. Some businesses hold data they cannot send to a third-party API at all. An Australian healthcare provider handling patient records, or a firm with contractual data-residency obligations shaped by the Privacy Act, may need the model to run inside its own controlled environment. In those cases, self-hosting in an AWS Sydney or Azure Australia East region can be the right call even when the per-token maths favours a managed service, because the real alternative is not doing the project at all. The skill is making that trade on purpose, with the numbers in front of you, rather than backing into it.
The honest recommendation
Self-hosting an open-source model is a sound choice for a narrow set of Australian businesses: high and steady volume, strict data-residency rules, and an in-house engineer who genuinely owns the system. For almost everyone else, a managed model like Claude paired with careful prompt and process design delivers the same business outcome for less money and a fraction of the risk.
Before you price up a GPU server, measure your actual token volume for a month. That one number settles most of these debates before they start. If you want a hand running the calculation against your real usage, you can book a free brainstorm with us and we will work through the figures together.